Table of Contents
OSPF Features
OSPF (Open Shortest Path First) is a routing protocol that can be used for large scale enterprise networks. It is the most commonly used routing protocol in enterprise internal networks. However, simply using OSPF is not enough for efficient routing in a large network. It is necessary to have a firm grasp of how OSPF works and design it appropriately.
The features of OSPF can be briefly summarized as follows.
- IGPs(Interior Gateway Protocols)
- Link State Routing Protocol
- The concept of “area” for efficient routing
- Classless Routing Protocol
- Routing table convergence time is short
- The possibility of loops occurring is extremely small
- Use ” path cost” as a metric
- Use of multicast
- Support for authentication feature
- High CPU and memory load
- Proper address design is needed
These features are explained in the following sections. You can also find links to pages with more detailed explanations. If necessary, please refer to the detailed explanation page as well.
IGPs
OSPF is a type of IGPs that, like RIP, targets routing inside an AS. In other words, OSPF is used for routing in enterprise internal networks, and is primarily intended for larger networks than RIP.
Related article
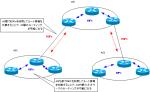
Link State Routing Protocol
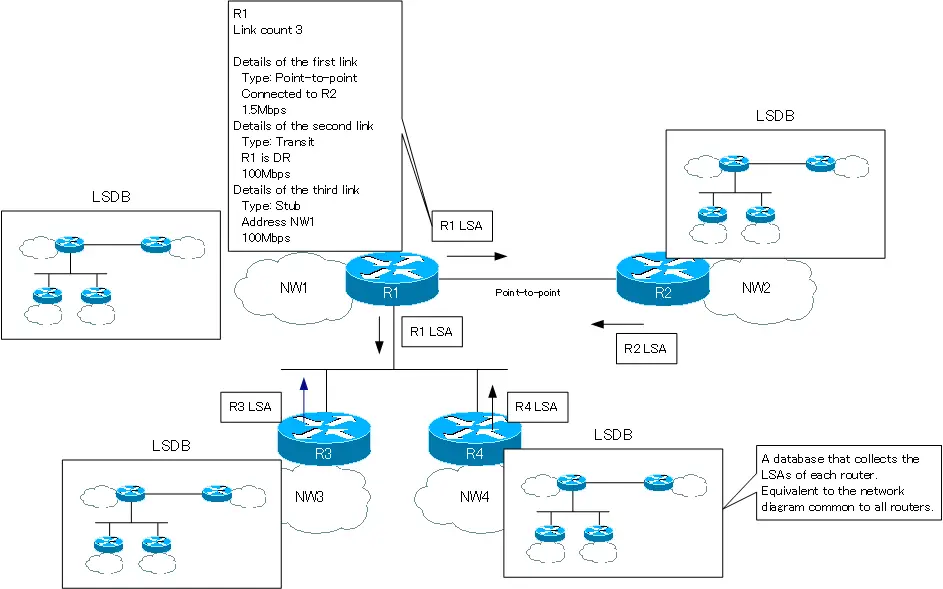
The routing algorithm of OSPF is link-state type. In the link state type, routers exchange LSA (Link State Advertisement) instead of simple network address/subnet mask. A link is a connection between OSPF-enabled interfaces. By exchanging the state of the links, each OSPF router can have a detailed view of the network diagram.
The LSAs exchanged by the OSPF router are stored in the Link State Database (LSDB). The LSDB is the detailed network diagram that each OSPF router is aware of. Then, the SPF (Shortest Path First) algorithm is used to determine the best route and create the routing table. The following figure shows how LSAs are exchanged in OSPF.
Related article
The following article and others provide detailed explanations of how LSAs are exchanged and LSDBs are synchronized.
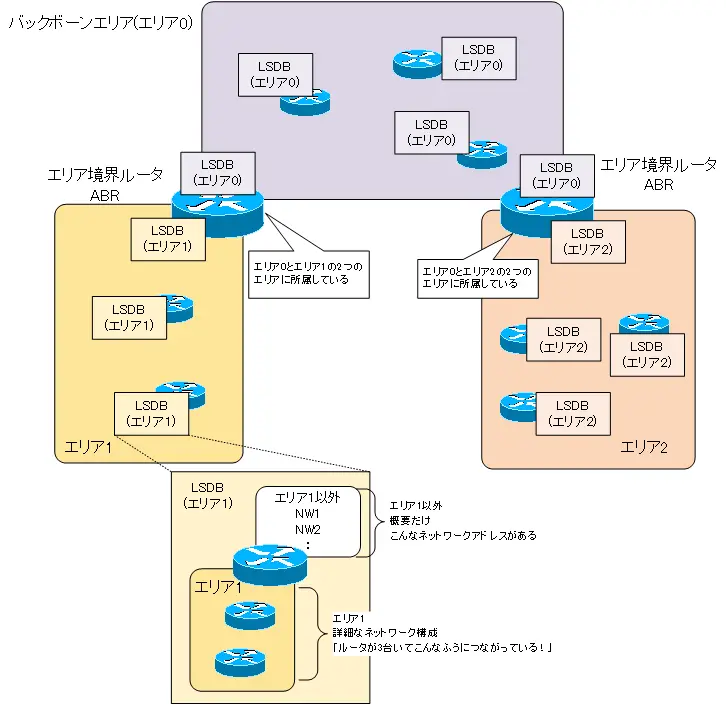
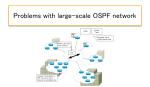
The concept of “area” for efficient routing
The link state database is common to all routers in an area. In large networks, the number and size of link-state information exchanged can be very large, and with it, the link-state database size can be huge. This results in consuming a lot of CPU cycles and memory in the router, which is undesirable. To solve these problems, OSPF introduces the concept of “areas” to enable more efficient routing in large networks. In order to use OSPF effectively, it is important to have a good understanding of the area.
An OSPF area is “a group of OSPF routers that have the identical LSDB”. Then, by dividing into areas, the LSDB describes the detailed network diagram inside the area, and only the overview outside the area.
Related article
The following article explains the area.
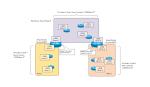
Classless Routing Protocol
OSPF is a classless routing protocol that recognizes network addresses based on subnet masks. The LSAs exchanged in OSPF also include subnet masks. Therefore, OSPF can support VLSM and discontinuous subnets, which cannot be supported by classful routing protocols such as RIPv1.
Related article
Classless routing protocols are explained in the following article.
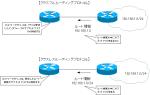
Routing table convergence time is short
All OSPF routers have a common map of the network, or link-state database, and adopt triggered updates that send LSAs only when there is a change in the network. Therefore, even if any changes occur, the triggers update allows each router to quickly recognize the changes and reflect the change information in the link state database and routing table. It is possible to converge much faster than a distance-vectored routing protocol such as RIP.
The possibility of loops occurring is extremely small
Each OSPF router maintains a link-state database that is a map of the entire network, and by using triggers updates, convergence is fast. Since changes in network configuration can be quickly reflected in the routing table, there is little chance of getting the routing table wrong and causing loops.
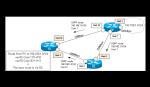
Use ” path cost” as a metric
OSPF uses the path cost as a criterion for optimal route selection. By default, the cost is automatically calculated according to the bandwidth of the interface. The accumulated cost to the destination network is the path cost. The route with the lowest path cost is the optimal route. The higher bandwidth, the lower the cost value, so in OSPF, the route with the higher bandwidth is considered optimal.
Related article
For more information about OSPF path costs, please see the following article
Use of multicast
Communication between OSPF routers is usually done via multicast (224.0.0.5 or 224.0.0.6). Therefore, there is no extra load on other hosts on the network or on routers that do not have OSPF enabled.
Support for authentication feature
In order to improve security, OSPF supports authentication feature. The authentication feature allows LSAs to be exchanged only between legitimate OSPF routers.
Related article
The following article explains the configuration of OSPF neighbor authentication.

High CPU and memory load
OSPF is a more complex process than RIP. Therefore, the load on the router’s CPU and memory is greater than using RIP.
Proper address design is needed
It is not limited to OSPF, but proper address design is necessary for efficient use of routing protocols. If the address design is not good enough, the route information cannot be summarized well.
Related article
Route summarization in OSPF is explained in the following article.

Main RFCs related to OSPF
The OSPF specification is defined in RFCs; the main OSPF-related RFCs are as follows
| Year of publication | RFC |
| 1989 | RFC1131 OSPF specification |
| 1991 | RFC1247 OSPF Version 2 |
| 1998 | RFC2328 OSPF Version 2 |
| 1999 | RFC2740 OSPF for IPv6 |
| 2008 | RFC5340 OSPF for IPv6 |
| 2010 | RFC5838 Support of Address Families in OSPFv3 |
How the OSPF works
- OSPF Overview
- OSPF process flow
- OSPF Router ID : Identify OSPF routers
- What if the router ID of the OSPF router is duplicated?
- OSPF Neighbor and Adjacency
- OSPF DR/BDR
- How show ip ospf neighbor looks on Ethernet
- OSPF Network Type : Classification of OSPF-enabled interfaces
- Synchronization process of OSPF LSDB
- Problems with large-scale OSPF network
- OSPF Area – Inside the area, in detail; outside the area, just a summary
- OSPF Router Type
- OSPF LSA Type
- OSPF Area Type
- OSPF Basic Configuration and Verification Commands
- Details of enabling OSPF on the interface
- OSPF Advertising Loopback Interface
- Configuring and Verifying OSPF Hello/Dead interval
- OSPF Cost Configuration and Verification
- Configuring and Verifying OSPF Router Priority
- Configuring OSPF Neighbor Authentication
- Neighbor Authentication over Virtual-link
- OSPF Configuring and Verifying Stub area [Cisco]
- OSPF Stub Area Configuration Example [Cisco]
- OSPF default route generation : default-information originate command
- Configuration Example of OSPF default route generation : stub area
- OSPF Virtual-Link : Virtual area 0 point-to-point link
- Configuring and Verifying OSPF Virtual-link [Cisco]
- OSPF Virtual-link Configuration Example [Cisco]
- OSPF Virtual-link for discontinuous backbone configuration example
- OSPF Route Summary and Configuration
- Cisco OSPF Route Summary Configuration Example
- OSPF Route Type Preference
- Why the OSPF neighbor state gets stuck in Exstart?
- OSPF packet type and header format
- OSPF Hello Packet
- OSPF DD(Database Description) Packet
- OSPF LSR(Link State Request) Packet
- OSPF LSU(Link State Update) Packet
- OSPF LSAck(Link State Acknowledgement) Packet
- Limitation of OSPF redistribution routes – redistribute maximum-prefix command
- Overview of LSA Filters for OSPF – Filter LSA Type 3/Type 5
- Configuration example of LSA type 3 filter
- Configuration example of LSA type 5 filter
- OSPFv3 Configuration Example [Cisco]
- Configuration Example of OSPFv3 Route Summary [Cisco]
